
Epidemics: The R Factor and Public Policy Choices
In my last post, I kind of assumed knowledge of how the R factor works and what it is. If you already know, you can skip this post. But I […]

In my last post, I kind of assumed knowledge of how the R factor works and what it is. If you already know, you can skip this post. But I […]

COVID related social restrictions aren’t there to protect you today. They won’t move the dial much on that point. They are there to protect us all in the medium term. This article explains the mathematics of why we need these measures even if the personal COVID risks are already at a risk level that’s “acceptable” without them.
Very shortly after the Brexit Referendum, I blogged about how it is not such a good idea to hold referenda at which irreversible decisions are able to be made by […]

“Doubt Kills More Dreams Than Failure” is a quote by Suzy Kassem, apparently. I admit I don’t know her, but the quote jumped out at me on a LinkedIn Post […]

What’s going on in the UK right now is already old hat: Scotland possibly planning another referendum, the young feeling disenfranchised by a ‘democratic’ vote, and MPs scratching their heads […]

Two big changes in international tax treaties have been in the works for some time: the BEPS (Base Erosion and Profit Shifting) Action Plan by the OECD, and debates within […]

If you can’t pay from own resources, this is what it comes down to, eventually. It’s definitely not a question of it, but of when. An article in Handelsblatt today […]

In many posts I refer much too briefly to the ‘misconstructed’ currency union. I think I need to dedicate a series now to explain in more detail what I mean […]

This is significant. The hashtag #Thisisacoup is trending massively on Twitter, leading Hugo Dixon, a keen observer of the Greek crisis, to suggest that the Eurozone in general is losing the […]

Varoufakis was too clever to understand politics. It is three years ago that I had an exchange with him on his blog about needing credible threats if one wanted to play […]
Here is a quote from Ryszard Legutko, MEP from the conservative group ECR: So if this piece de theatre continues I think we will be more and more confused about […]

I am in utter disbelief: There was an emergency Eurogroup finance ministers meeting, and there will be a Eurogroup leaders meeting in an hour, and Greece turned up without a […]

Here is what Tsipras should say to Europe. No fancy victory lap rhetoric, just the facts: Greek voters have made their view clear. There is not even a single electoral […]

The IMF has left the realms of delusion over Greek debt sustainability. It now has admitted that it failed to realise the damage austerity would do. In other words the deal which […]

With Greece defaulting tomorrow, my post two weeks ago “Greece: Why is it so important?” seems more eerily prescient than I feared back then. I said the Greek government isn’t […]

The game of chicken is over. There is no stepping back from the promise of a referendum, and if there is a future ‘deal’, it won’t be with the current […]
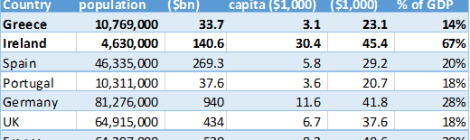
Before the next crunch-time comes for Grexit negotiations on Monday, let’s study why austerity hasn’t worked in Greece, and why Ireland, by contrast, didn’t seem to have suffered adverse consequences. The openness […]

It’s often been said in the last days that Greece represents less than 2% of the Eurozone’s GDP, so we shouldn’t spend so much energy on the whole Greek situation, […]

In an inversion of the closing of Tsipras’ op-ed in Le Monde, we might ask: Does the bell really toll for Europe, or just for Greece? The game of the […]

Much has been made of the Greek Finance Minister’s credentials in game theory. Because I commute to Greece a lot, and because I’ve had some exchanges with Yanis Varoufakis on […]

You must be logged in to post a comment.